來源:硅兔賽跑
世間建筑可以分為兩種,一種是集市,天天開放在那里,從無到有,從小到大;一種是教堂,幾代人嘔心瀝血,歷盡幾十年方能完工。Eric Raymond在《大教堂與集市》中如是寫道。
而Linux的故事,更像是用集市的方式,建造一座大教堂。如今,在生成式人工智能領(lǐng)域,越來越多的開源模型正在為這樣的“建造模式”貢獻(xiàn)新的案例。
阿里云,是開源模型的堅(jiān)定追逐者。目前,通義千問Qwen衍生模型數(shù)量已突破10萬,超越美國Llama模型,通義成為全球第一AI開源模型。
4月29日凌晨,阿里發(fā)布新一代通義千問模型Qwen3(簡(jiǎn)稱千問3),參數(shù)量?jī)H為DeepSeek-R1的三分之一,為235B,成本大幅下降。
據(jù)悉,千問3是國內(nèi)首個(gè)“混合推理模型”,“快思考”與“慢思考”集成進(jìn)同一個(gè)模型,對(duì)簡(jiǎn)單需求可低算力“秒回”答案,對(duì)復(fù)雜問題可多步驟“深度思考”,大大節(jié)省算力消耗。
2023年至今,阿里通義團(tuán)隊(duì)已經(jīng)開源了200多款模型,包含大語言模型千問Qwen及視覺生成模型萬相Wan等兩大基模系列,開源囊括文本生成模型、視覺理解/生成模型、語音理解/生成模型、文生圖及視頻模型等全模態(tài),覆蓋從小到大全尺寸參數(shù),滿足不同的終端需求。
千問3的總參數(shù)量為235B,激活僅需22B。千問3預(yù)訓(xùn)練數(shù)據(jù)量達(dá)36T ,并在后訓(xùn)練階段多輪強(qiáng)化學(xué)習(xí),將非思考模式無縫整合到思考模型中。
千問3的部署成本還大幅下降,僅需4張H20即可部署千問3滿血版,顯存占用僅為性能相近模型的三分之一。
阿里的開源模型發(fā)布,對(duì)行業(yè)意味著什么?開源模型的能力如何?未來的大模型競(jìng)爭(zhēng)將會(huì)走向何方?
開源大模型的能力正在趕上閉源模型。
這是筆者在詢問了多位AI創(chuàng)業(yè)者、大廠大模型開發(fā)者及投資人后的共識(shí)。
盡管,他們也同意,如今還是閉源模型處于領(lǐng)先地位,但開源模型和閉源模型之間的差距正在逐步縮小,而這樣的速度,令業(yè)界始料未及。
“閉源模型先做到了90分,但如今,開源模型也能夠做到90分的水平。”一位大模型開發(fā)人員表示。Scaling Law總有瓶頸,這個(gè)瓶頸所體現(xiàn)的便是模型越大,能力提升、付出的成本則是成倍增加,因此給了開源模型追趕的時(shí)間。
是開源模型究竟開放了什么?其與開源軟件有什么區(qū)別?又與閉源模型的差異體現(xiàn)在哪里?
開源軟件通常是公開源代碼的全貌,允許開發(fā)者查看、修改,后續(xù)開發(fā)者可以很容易根據(jù)代碼復(fù)現(xiàn)相應(yīng)的功能實(shí)現(xiàn)。但開源模型一般只開源參數(shù),至于其中用了什么數(shù)據(jù)、如何微調(diào)、如何對(duì)齊,卻難以知曉。閉源模型則是直接提供一整套方案。可以理解為,開源模型是基于原有的材料,需要廚師自備工具、菜單、研究做法,但究竟能不能做出一道好菜,全靠廚師功力。閉源模型則是預(yù)制菜,加熱即用。
但開源模型的好處在于,能夠讓更多開發(fā)者參與到模型的開發(fā)中,幫助模型提升性能、完善生態(tài),并且靈活性強(qiáng)。這能夠幫助模型公司省去很多人力成本和時(shí)間成本。對(duì)于使用開源模型的一方,也是一種節(jié)省成本的方式。
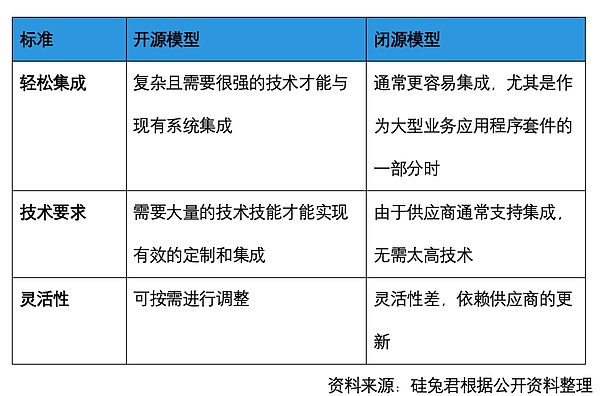
不過,開源模型的成本優(yōu)勢(shì)在前期,舉個(gè)例子,據(jù)計(jì)算,閉源模型GPT-4每百萬個(gè)代幣輸入的成本約為10美元,每百萬個(gè)代幣輸出的成本約為30美元,而開源模型Llama-3-70-B每百萬個(gè)代幣輸入的成本約為 60 美分,每百萬個(gè)代幣輸出的成本約為 70 美分,這使其成本大約便宜 10 倍,而性能差異卻很小。但如果涉及到后續(xù)的部署,則需要極強(qiáng)的技術(shù)實(shí)力和投入。
不過,阿里此次發(fā)布的千問3,也正在逐步解決成本投入的問題,以阿里新發(fā)布的千問3為例,從部署成本看,千問3是滿血版R1的25%~35%,模型部署成本大降六/七成。旗艦版千問3模型的總參數(shù)235B激活22B,大致需要4張H20或同等性能的GPU。對(duì)比來看,滿血版DeepSeek-R1總參數(shù)671B激活37B,1臺(tái)8卡H20雖然可跑,但較吃緊(100w左右),一般推薦16卡H20,總價(jià)約200萬左右。
模型推理上看,千問3獨(dú)特的混合推理模型,開發(fā)者可自行設(shè)置“思考預(yù)算”,在滿足性能需求的同時(shí)實(shí)現(xiàn)更精細(xì)化的思考控制,自然也會(huì)節(jié)省整體推理成本。可以參考的是,同類型的Gemini-2.5-Flash在定價(jià)上的推理和非推理模式的價(jià)格相差約6倍,用戶使用非推理模式時(shí)相當(dāng)于可節(jié)省600%的算力成本。
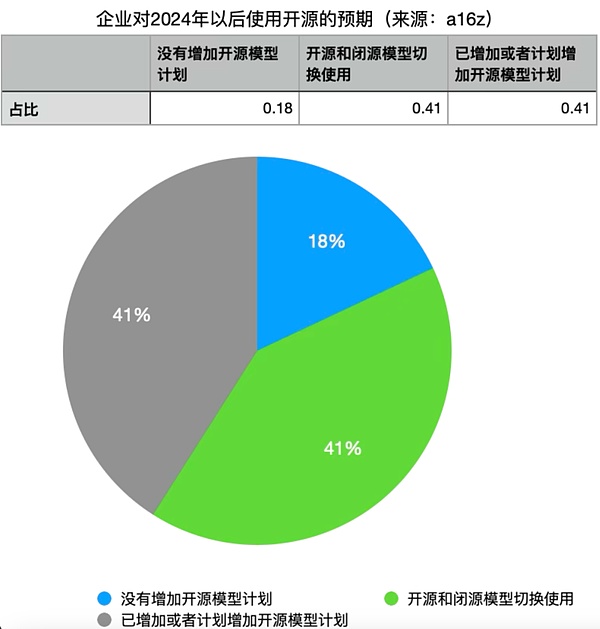
一位大廠從事大模型開發(fā)人員告訴硅兔君,開源模型更適合于有很強(qiáng)技術(shù)實(shí)力,但沒有足夠預(yù)算的團(tuán)隊(duì),例如學(xué)術(shù)機(jī)構(gòu)。而閉源模型則適合人少錢多的公司。不過,隨著開源模型能力的提升,有41%的受訪企業(yè)計(jì)劃增加對(duì)開源模型的使用,而41%的企業(yè)認(rèn)為如果開源模型和閉源模型性能相當(dāng),會(huì)轉(zhuǎn)向開源模型。在這項(xiàng)調(diào)查中,僅有18%的企業(yè)不打算增加對(duì)開源LLM的使用。
A16z創(chuàng)始人馬克·安德里森就表示,開源,讓大學(xué)重新回到競(jìng)爭(zhēng)中,因?yàn)椋绻芯空叩膿?dān)心是,第一,大學(xué)沒有足夠的資金來參與AI領(lǐng)域的競(jìng)爭(zhēng)并保持相關(guān)性;其次,所有大學(xué)加在一起也沒有足夠的資金來參與競(jìng)爭(zhēng),因?yàn)闆]有人能夠跟上這些大型公司的籌資能力。而當(dāng)開源模型越來越多且能力上來之后,就意味著大學(xué)可以使用開源模型進(jìn)行研究。對(duì)沒有足夠資金的小公司而言,這個(gè)邏輯同樣成立。
?硅兔君制圖
DeepSeek的橫空出世,讓諸多人發(fā)現(xiàn)了中國公司開源模型的能力。
“Deep Seek代表的是輕量化、低成本的AI產(chǎn)品。”一位中美AI投資人表示,舉個(gè)例子,混合專家模型(MoE)的調(diào)整需要極高的工藝,過去的主流模型使用MoE的并不多,是因?yàn)殡y,但是“小孩不信邪”,卻把這件事做成了。
但開源模型最重要的是生態(tài),也就是說到底有多少人用。畢竟,要切換不同的模型,對(duì)用戶而言是極高的成本。不過,當(dāng)DeepSeek橫空出世之后,在硅谷一些用Meta的大模型的用戶也切換到了DeepSeek,“后來者一定要比先發(fā)者有足夠的優(yōu)勢(shì)。”一位大模型研發(fā)人員表示,這樣才會(huì)吸引用戶放棄前期投入的成本,切換到新的開源模型上來。
硅兔君整理了目前全球知名模型的開源和閉源情況發(fā)現(xiàn),除了亞馬遜,微軟、谷歌、Meta、OpenAI都有開源模型的布局,一些公司選擇純開源路線、一些選擇開源和閉源并行,在中國,阿里是在開源道路上走得最堅(jiān)定的大廠。早在DeepSeek發(fā)布R1前,阿里就在開源模型上押注和布局。
全球知名模型開源情況


根據(jù)李飛飛的《斯坦福人工智能報(bào)告2025》,2024年中,阿里發(fā)布的著名AI大模型數(shù)量為6個(gè),位于全球第三,谷歌和Open AI并列第一,為7個(gè)。而在報(bào)告中所提及的2024年重要大模型排名,阿里的AI貢獻(xiàn)度位列全球第三。
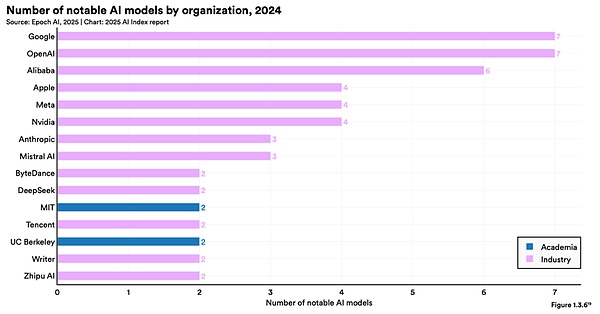
來源:《斯坦福人工智能報(bào)告2025》
而29日發(fā)布的千問3,作為通義千問系列最新一代大語言模型,提供了一系列稠密(Dense)和混合專家(MoE)模型。在推理、指令跟隨、智能體能力和多語言支持方面取得了突破性的進(jìn)展,具有以下特性:
1) 獨(dú)特的混合推理:支持在思考模式 (用于復(fù)雜邏輯推理、數(shù)學(xué)和編碼)和 非思考模式 (用于高效通用對(duì)話)之間無縫切換,確保在各種場(chǎng)景下的最佳性能。
2) 顯著增強(qiáng)的推理能力 :在數(shù)學(xué)、代碼生成和常識(shí)邏輯推理方面超越了之前的 QwQ(在思考模式下)和Qwen2.5-Instruct 指令模型(在非思考模式下)。
3) 更好的人類偏好對(duì)齊 :在創(chuàng)意寫作、角色扮演、多輪對(duì)話和指令跟隨方面表現(xiàn)出色,提供更自然、更吸引人和更具沉浸感的對(duì)話體驗(yàn)。
4) 智能體能力突出 :可以在思考和非思考模式下精確集成外部工具,在復(fù)雜的基于代理的任務(wù)中在開源模型中表現(xiàn)領(lǐng)先。
5) 強(qiáng)大的多語言能力:支持119 種語言和方言,具備強(qiáng)大的多語言指令跟隨和翻譯能力。
其中所提到的“混合推理”,相當(dāng)于把頂尖的推理模型和非推理模型集成到同一個(gè)模型里去,需要極其精細(xì)、創(chuàng)新的設(shè)計(jì)及訓(xùn)練。目前,熱門模型中只有千問3、Claude3.7以及Gemini 2.5 Flash可以做到。
具體而言,在“推理模式”下,模型會(huì)執(zhí)行更多中間步驟,如分解問題、逐步推導(dǎo)、驗(yàn)證答案等,給出更深思熟慮的答案;而在“非推理模式”下,模型會(huì)直接生成答案。同一個(gè)模型,可以完成“快思考”和“慢思考”,這類似于人類在回答簡(jiǎn)單問題時(shí),憑經(jīng)驗(yàn)或直覺快速作答,面對(duì)復(fù)雜難題時(shí)再深思熟慮,仔細(xì)思考給出答案。千問3還可API設(shè)置“思考預(yù)算”(即預(yù)期最大thinking tokens數(shù)量),進(jìn)行不同程度的思考,讓模型在性能和成本間取得更好的平衡,以滿足開發(fā)者和機(jī)構(gòu)的多樣需求。
Qwen3的性能情況
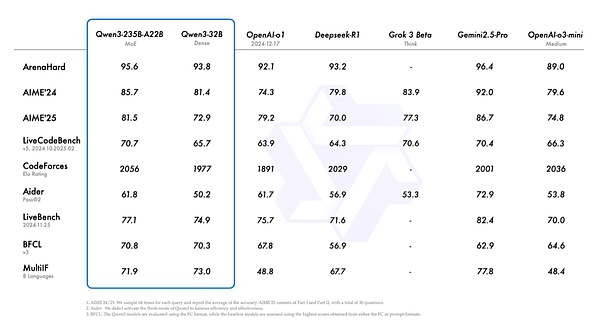
對(duì)中國而言,開源模型的做法也比閉源模型能夠吸引更多客戶,因?yàn)槿绻情]源的模型,只能更多集中在國內(nèi)市場(chǎng),但開源則能夠讓更多國外公司也進(jìn)行使用,舉個(gè)例子:Perplexity是一家美國公司,但用戶可以在Perplexity上使用DeepSeek R1,并完全托管在美國,使用美國的數(shù)據(jù)中心。
2023年3月,在舊金山的探索館一場(chǎng)開源AI盛會(huì)上,羊駝漫步在會(huì)場(chǎng)上,致敬了Meta的開源大語言模型“LLaMA”。
2023年至今,一年多時(shí)間里,生成式AI正在不斷發(fā)生變化。公眾的關(guān)注點(diǎn)已從基礎(chǔ)模型變?yōu)锳I原生的應(yīng)用。在YC W25的Demo Day中,80%的項(xiàng)目都是AI應(yīng)用。
“開源模型將會(huì)促進(jìn)更多Agent的落地。”多位業(yè)界人士向硅兔君表達(dá)了這個(gè)觀點(diǎn)。一方面是開源將會(huì)降低使用成本及門檻。
例如千問3 有很強(qiáng)的工具調(diào)用能力,在伯克利函數(shù)調(diào)用BFCL評(píng)測(cè)榜中,千問3創(chuàng)下70.76的新高,將大幅降低Agent調(diào)用工具的門檻。同時(shí),可結(jié)合 Qwen-Agent 開源框架來充分實(shí)現(xiàn)Qwen3 的智能體能力。Qwen-Agent 是一個(gè)基于 Qwen 的指令跟蹤、工具使用、規(guī)劃和內(nèi)存功能開發(fā) LLM 應(yīng)用程序的框架,框架內(nèi)部封裝了工具調(diào)用模板和工具調(diào)用解析器,還附帶瀏覽器助手、代碼解釋器和自定義助手等示例應(yīng)用程序,大大降低了編碼復(fù)雜性。千問3原生支持MCP協(xié)議,開發(fā)者要定義可用工具,可基于 MCP 配置文件,使用 Qwen-Agent 的集成工具或自行集成其他工具,快速開發(fā)一個(gè)帶有設(shè)定、知識(shí)庫RAG和工具使用能力的智能體。
不僅如此,阿里的千問3能夠支持不同尺寸模型,千問3對(duì)手機(jī)、智能眼鏡、智能駕駛、人形機(jī)器人等智能設(shè)備和場(chǎng)景的部署更為友好,所有企業(yè)都可免費(fèi)下載和商用千問3系列模型,這也將大大加速AI大模型在終端上的應(yīng)用落地。
另外,有從業(yè)者指出,閉源模型在To B端并沒有很好解決信任問題,很多大企業(yè)其實(shí)并不愿意將自己的業(yè)務(wù)接入第三方大模型的API,因?yàn)檫@背后是核心數(shù)據(jù)是否會(huì)成為第三方大模型訓(xùn)練的一部分,這也是開源模型的機(jī)會(huì)。
有一個(gè)說法是,開源作為早期產(chǎn)品,在沒有經(jīng)過beta測(cè)試之前的市場(chǎng)推廣策略,當(dāng)不知道明天會(huì)是什么樣的時(shí)候,先開源出來,吸引開發(fā)者。當(dāng)有人用起來的時(shí)候,就有了最佳實(shí)踐,緊接著就建立起了自己的生態(tài)。
不過,由于開源模型的商業(yè)鏈條較長(zhǎng),不如閉源模型來得快和清晰,因此業(yè)界人士表示,開源模型更多適合家里有錢有資源的“富二代”的游戲。以Meta來說,Meta做開源模型,更多是搭建生態(tài),為Meta其他業(yè)務(wù)板塊提供支持。阿里做開源的邏輯,則更多是為其云服務(wù)。阿里有很強(qiáng)的云設(shè)施服務(wù),可以在此基礎(chǔ)上訓(xùn)練大模型,另外也可以將大模型部署在自己的云服務(wù)商,甚至可以根據(jù)用戶部署定制專屬大模型,用這樣的方式走通商業(yè)邏輯。
“我的模式是,讓大公司、小公司和開源相互競(jìng)爭(zhēng)。這就是計(jì)算機(jī)行業(yè)發(fā)生的事情。”馬克·安德里森曾表示。而在大模型逐漸變成如水、電、煤一樣的標(biāo)準(zhǔn)化產(chǎn)品,開源可能更適合未來的方向。
 喜來順財(cái)經(jīng)
喜來順財(cái)經(jīng)