作者:霧月,極客web3
眾所周知,EVM的定位是以太坊的“執行引擎”和“智能合約執行環境”,可以說是以太坊最重要的核心組件之一。公鏈是一個包含成千上萬節點的開放性網絡,不同節點的硬件參數相差甚大,若想讓智能合約在多個節點上都跑出相同結果,滿足“一致性”,要設法在不同設備上都搭建出相同的環境,而虛擬機可以實現這個效果。
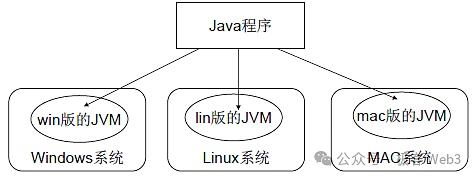
以太坊的虛擬機EVM能在不同操作系統(如Windows、Linux、macOS)和設備上以相同的方式來運行智能合約,這種跨平臺兼容性確保每個節點運行合約后,都能得到一致的結果。最典型的例子就是Java虛擬機JVM。
我們平時在區塊瀏覽器里看到的智能合約,都是先被編譯為EVM字節碼,然后才存儲到鏈上的。EVM在執行合約時,直接按順序讀取這些字節碼,字節碼對應的每條指令(opCode)都有相應的Gas成本。EVM會跟蹤每條指令在執行過程中的Gas消耗,消耗量則取決于操作的復雜度。
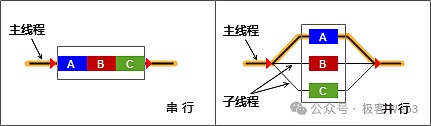
此外,作為以太坊的核心執行引擎,EVM采用串行執行的方式處理交易,所有交易在單一隊列里排隊并按照確定順序先后執行。之所以不用并行化的方式,是因為區塊鏈要嚴格滿足一致性,一批交易在所有節點中都要按相同次序來處理,如果將交易處理并行化,難以精確的預判交易次序,除非引入對應的調度算法,但這會比較復雜。
2014~15年的以太坊創始團隊出于時間緊迫,選用了串行執行的方式。因為它設計簡單且易于維護。然而隨著區塊鏈技術的迭代和用戶群體越來越大,區塊鏈對TPS和吞吐量的要求越來越高,在Rollup技術出現并成熟落地后,EVM串行執行帶來的性能瓶頸在以太坊二層身上已經暴露無疑。
Sequencer作為Layer2的關鍵組件,以單個服務器的形式承接所有運算任務,如果與Sequencer配合的外部模塊的效率都足夠高,則最終的瓶頸將取決于Sequencer本身的效率,此時串行執行將成為巨大的阻礙。
opBNB團隊曾通過對DA層和數據讀寫模塊進行極致優化,Sequencer每秒最多可執行約2000多筆ERC-20轉賬。這個數字看起來很高,但如果要處理的交易比ERC-20轉賬復雜很多,TPS數值必然會大打折扣。所以說,交易處理的并行化將是未來的必然趨勢。
下面我們將從更具體的細節入手,為大家詳細解釋傳統EVM的局限性,以及并行EVM的優勢。
以太坊交易執行的兩大核心組件
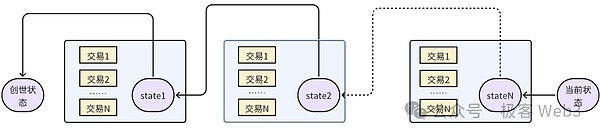
在代碼模塊層面,除EVM外,go-ethereum中與交易執行相關的另一核心組件是stateDB,用于管理以太坊中的賬戶狀態和數據存儲。以太坊采用名為Merkle Patricia Trie的樹狀結構來充當數據庫索引(目錄),EVM每一次交易執行都會變更stateDB中存放的某些數據,這些變更最終會反映在Merkle Patricia Trie(后面簡稱全局狀態樹)中。
具體來說,stateDB負責維護所有以太坊賬戶的狀態,包括EOA賬戶和合約賬戶,其存儲的數據包括賬戶余額、智能合約代碼等。在交易執行過程中,stateDB會對相應賬戶的數據進行讀寫。而在交易執行結束后,stateDB需要將新的狀態提交到底層數據庫(如LevelDB)中,進行持久化處理。
總的來說,EVM負責解釋和執行智能合約指令,根據計算結果變更區塊鏈上的狀態,而stateDB則充當全局狀態存儲,管理所有賬戶和合約的狀態變化。兩者協作構建了以太坊的交易執行環境。
串行執行的具體過程
以太坊的交易類型分兩種,即EOA轉賬和合約交易。EOA轉賬是最簡單的交易類型,即普通賬戶之間的ETH轉賬。這種交易不涉及合約調用,處理速度非常快。由于操作簡單,EOA轉賬收取的gas費極低。
與簡單的EOA轉賬不同,合約交易會涉及到智能合約的調用與執行。EVM在處理合約交易時,要逐條解釋和執行智能合約中的字節碼指令,合約的邏輯越復雜,涉及的指令越多,消耗的資源越多。
舉例來說,ERC-20轉賬的處理時間大約是EOA轉賬的2倍,而對于更復雜的智能合約,如Uniswap上的交易操作,耗時更長,甚至可以比EOA轉賬慢十幾倍。這是因為DeFi協議需要在交易時處理流動性池、價格計算、代幣swap等復雜邏輯,需要進行非常復雜的計算。
那么在串行執行模式下, EVM與stateDB這兩個組件是如何協作處理交易的呢?
在以太坊的設計中,一個區塊內的交易會按先后次序被一筆筆處理,每筆交易(tx)都會有一個獨立實例,用于執行該交易的具體操作。盡管每筆交易會使用不同的EVM實例,但所有交易要共用同一個狀態數據庫,也就是stateDB。
在交易執行過程中,EVM需要不斷與stateDB交互,從stateDB中讀取相關的數據,并將變更后的數據寫回stateDB。
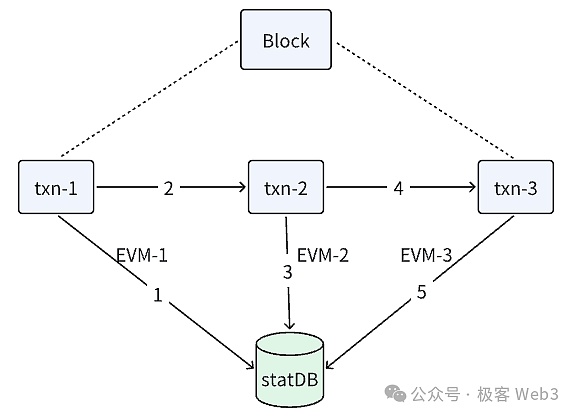
我們從代碼角度大致看下EVM和stateDB是如何協作執行交易的:
1. processBlock()函數會調用Process()函數處理一個區塊中包含的交易;

2. Process()函數中定義了一個for循環,可以看到交易是被一筆一筆執行的;

3. 在所有交易處理完畢后,processBlock()函數調用writeBlockWithState()函數,再調用statedb.Commit()函數,提交狀態變更結果。
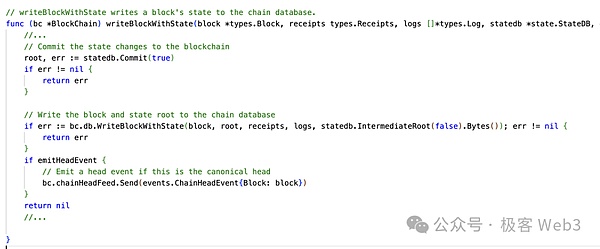
當一個區塊中所有交易都被執行完畢后,stateDB中的數據會被Commit到前面提到的全局狀態樹(Merkle Patricia Trie),并生成新的狀態根(stateRoot)。狀態根是每個區塊中的重要參數,它記錄了區塊執行后新的全局狀態的“壓縮結果”。
我們不難理解,EVM的串行執行模式瓶頸很明顯:交易必須按順序排隊執行,如果出現耗時很久的智能合約交易,在其處理完畢前,其他交易只能等待,這顯然無法充分利用CPU等硬件資源,效率會受到較大限制。
EVM的多線程并行優化方案
如果用生活中的例子來對比串行執行與并行執行,前者類比為只有一個柜臺的銀行,并行EVM則類比為有多個柜臺的銀行。在并行模式下,可以開啟多個線程同時處理多筆交易,效率可以得到幾倍速的提升,但棘手的地方在于狀態沖突問題。
如果多筆交易都聲明要改寫某個賬戶的數據,當它們被同時處理時,就會產生沖突,比如某NFT僅能鑄造1個,而交易1和交易2都聲明要鑄造該NFT,如果他們的請求都得到滿足,顯然會出現錯誤,應對這類情況需要進行協調處理。實際操作中的狀態沖突往往比我們提到的更頻發,所以如果要將交易處理并行化,就必須要有應對狀態沖突的措施。
Reddio對EVM的并行優化原理
我們可以看一下ZKRollup項目Reddio對EVM的并行優化思路。Reddio的思路是為每個線程都分配一筆交易,并在每個線程中提供一個臨時的狀態數據庫,稱為pending-stateDB。具體細節如下:
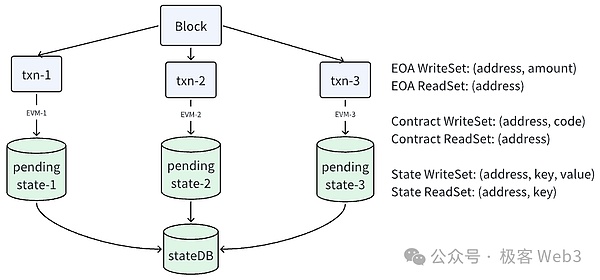
1. 多線程并行執行交易:Reddio設置多個線程同時處理不同的交易,線程之間互不干擾。這可以幾倍速提升交易處理速度。
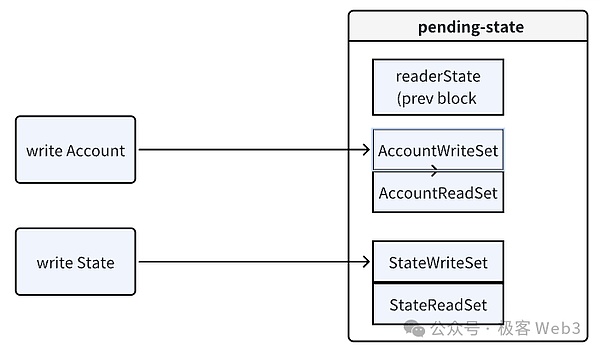
2. 為每個線程分配臨時狀態數據庫:Reddio為每個線程都分配一個獨立的臨時狀態數據庫(pending-stateDB)。各個線程在執行交易時,不會直接修改全局的stateDB,而是將狀態變化結果暫時記錄在pending-stateDB中。
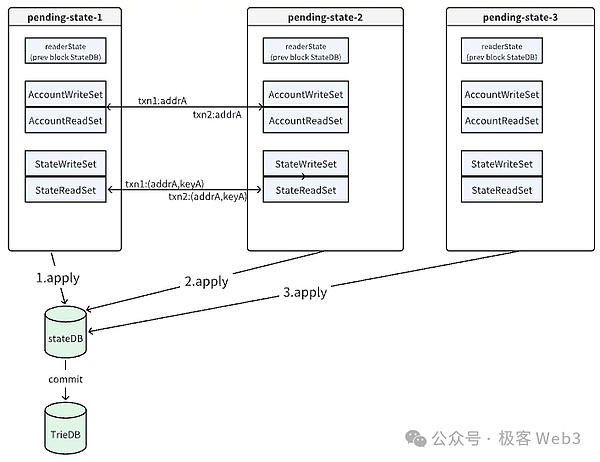
3. 同步狀態變更:在一個區塊內的所有交易都執行完畢后,EVM會將每個pending-stateDB中記錄的狀態變更結果依次同步到全局stateDB中。如果不同交易在執行過程中沒有發生狀態沖突,就可以將pending-stateDB中的記錄順利合并到全局stateDB中。
Reddio對讀寫操作的處理方式進行了優化,以確保交易能夠正確訪問狀態數據并避免沖突。
·讀操作:當一個交易需要讀取狀態時,EVM會首先檢查Pending-state的ReadSet。如果ReadSet顯示存在所需數據,EVM就直接從pending-stateDB中讀數據。如果ReadSet中沒有找到對應的key-value(鍵值對),就從上一個區塊對應的全局stateDB中讀取歷史狀態數據。
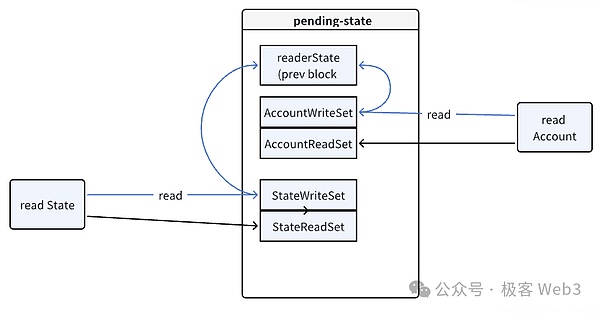
·寫操作:所有寫操作(即對狀態的修改)都不會直接寫入全局stateDB,而是先記錄到Pending-state 的WriteSet中。待交易執行完成后,通過沖突檢測再嘗試將狀態變更結果合并到全局stateDB中。
并行執行的關鍵問題在于狀態沖突,當多筆交易嘗試讀寫相同賬戶的狀態時,該問題尤為顯著。為此Reddio引入了沖突檢測機制:
· 沖突檢測:在交易執行過程中,EVM會監測不同交易的ReadSet和WriteSet。如果發現多個交易嘗試讀寫相同的狀態項,則視為發生沖突。
· 沖突處理:當檢測到沖突時,沖突交易將被標記為需要重新執行。
在所有交易都執行完成后,多個pending-stateDB中的變更記錄會被合并到全局stateDB中。如果合并成功,EVM會將最終狀態提交到全局狀態樹中,并生成新的狀態根。
多線程并行優化對性能的提升是顯而易見的,特別是應對復雜智能合約交易時。
根據并行EVM的研究顯示,在低沖突工作負載(交易池中較少矛盾的或者占用相同資源的交易)中,基準測試的TPS相比傳統的串行執行,提升了3~5倍左右。在高沖突工作負載中,理論上如果將所有優化手段都用上甚至可以達到60倍。
總結
Reddio的EVM多線程并行優化方案,通過為每個交易分配臨時狀態庫,并在不同線程中并行執行交易,顯著提高了EVM的交易處理能力。通過優化讀寫操作和引入沖突檢測機制,EVM系公鏈能夠在保證狀態一致性的前提下,實現交易的大規模并行化,解決了傳統串行執行模式帶來的性能瓶頸。這為以太坊Rollup未來的發展奠定了重要基礎。
后續我們會進一步深入分析Reddio的實現細節,如如何進一步從優化存儲效率提升效率,沖突高發時的優化方案,以及如何借助GPU做優化等等內容。
 喜來順財經
喜來順財經