作者:陳默 來源:cmdefi?
Justine Moore 花了6個月的時間做一項實驗,每天與ChatGPT交流,不斷分享個人想法和情感,試圖創建一個真正理解自己的“AI大腦”,結果AI的能力完全超出預期,她列舉了以下幾個場景:
1. 與他人溝通:通過使用大語言模型(LLM),可以幫助我們更清晰地傳達復雜的想法,大幅提升溝通能力。
這一點本身我自己也在用,目前我用到的AI最強能力,我覺得就是總結和溝通能力,如果你的總結能力比較欠缺,特別是對于在需要把一件事情或是一個項目給別人講清楚的情況下,利用AI學習總結和溝通能力真的是太強了。
2. 自我理解:AI大腦能夠很好地“心理分析”你,幫助你更清楚地認識自己的優勢和弱點,糾正認知偏見。
3. 與應用程序交互:AI大腦可以被帶入其他應用,解鎖真正個性化的體驗,比如一個完全理解你風格的寫作助手,或為你量身定制的工作或社交工具。
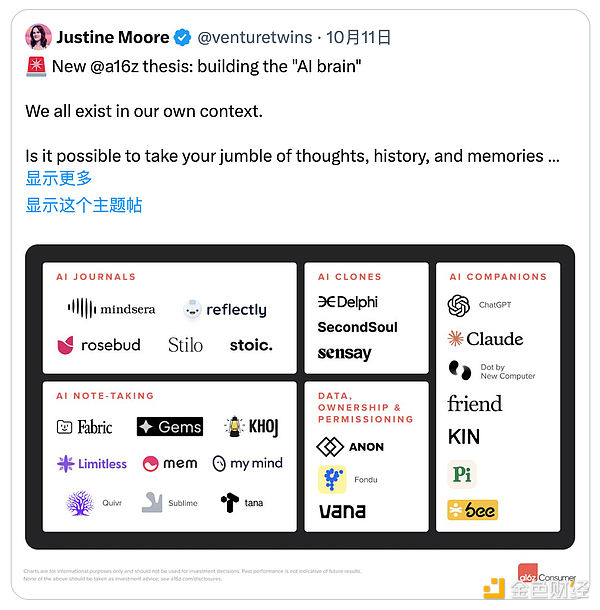
實際上如果你是一個重度AI使用者,可能已經有過類似的體驗,至少我覺得未來每個人都會有一個適配自己的AI大腦。
1. 用戶數據的完整性與質量
要讓AI大腦真正理解你,首先需要大量且高質量的個人數據。這包括你的歷史對話、行為記錄、情感傾向、偏好和決策等。數據越豐富越完整,AI大腦越能夠完美捕捉你的思維模式和個性。
2. 數據的私密性與安全性
個人數據的隱私保護至關重要,因為它已經學習了你大量的生活習性、性格喜好,甚至弱點缺陷。在構建“AI大腦”時,用戶需要對數據有完全的控制權,確保這些數據不會被濫用或泄露。畢竟,你的AI大腦最好不要讓別人入侵。
3. 透明的模型訓練和數據使用機制
一個真正理解自己的AI大腦,透明度是關鍵。用戶應該知道他們的數據如何被使用、AI模型如何訓練,這也可以被理解是安全性的一種。
在Justine的理念中,也基于以上3條,AI大腦應該完全掌握在用戶手中,避免大科技公司對數據的壟斷和利用。
所以,去中心化的架構可能成為一條通道,它可以通過讓用戶成為數據和AI模型的實際所有者,確保用戶在數據和AI模型的整個生命周期中都保持對其貢獻的控制和利益相關性。
這一方案的核心理念是 -賦予用戶對數據的完全主權,這基本與“AI大腦”的理念完全契合。
Vana引入“非托管數據”的概念,確保數據僅用于用戶授權的操作。用戶始終擁有對自己數據的控制權,不會被平臺或第三方托管。
實現方式就是,數據在貢獻給服務器之前會進行加密處理。每個用戶將自己的數據通過服務器的公鑰進行加密,確保即使數據被傳輸到集體服務器或用于AI訓練時,數據本身仍然是保密的,只有擁有解密密鑰的參與者才能解密和訪問數據。
這一點不僅解決了用戶的數據主權和隱私性,也為數據質量奠定了基礎,這也很重要,因為保證了隱私性,用戶才能沒有顧慮的提供真實數據,配合Vana區塊鏈的貢獻證明(Proof-of-Contribution)機制,加入了Crypto已經深入骨髓的代幣激勵模型,能夠讓用戶更加有動力去提供高質量數據。
綜合來說,Vana DataDAO 主要解決的就是數據主權問題,當然包括數據隱私和安全。事實上想訓練一個AI助手并不難,很多訓練語言模型的API都能夠提供這種環境,但未來我們的需求是否只會滿足于一個“助手”?AI 就像一個潘多拉魔盒,打開之后釋放出的魔力之強大可能越來越讓人難以拒絕,如果人類的需求上升到AI大腦、AI超級大腦的級別,關于數據主權的問題就不可避免。
 喜來順財經
喜來順財經